When combined with a distributed-microkernel OS, today's highly-efficient manycore processors can endow autonomous systems with human-like skills, explains Rolland Dudemaine, VP Engineering, eSOL Europe.
Today's autonomous machines and advanced industrial automation are increasingly expected to perform functions that humans are particularly good at, such as object recognition, contextual awareness, and decision making. Many are classified as edge devices that are independently able to capture, filter, grade, and use or discard vast quantities of information. Minimizing data exchanged with the cloud helps reduce bandwidth costs and protects time-critical processes against the adverse effects of latency.
Deterministic real-time performance is usually needed in applications such as autonomous-driving systems, industrial robots, and precision industrial automation, to ensure the reliability of control loops. On the other hand, power constraints are usually tight, often because the system is battery-powered, or a large, bulky power supply is undesirable from a size or weight standpoint (SWaP). Some applications, such as automotive systems, drones, or mobile robots, are subject to all of these considerations.
Although we are looking for these systems to replicate human capabilities, the human brain itself sets a high bar in terms of energy efficiency. Its enormous range of skills and real-time multi-tasking abilities represent processing performance equivalent to somewhere between 10Tera-FLOPS (10^12) and 10Yotta FLOPS (10^25), while consuming only about 20 Watts.
Conventional CPUs, DSPs, GPUs, and multicore including hybrid processors have not come close to the brain's combination of high performance and low power. A leading GPU such as the Nvidia K80 (GK210), for example, tops out at about 1.87TFLOPS although power consumption is 300W. But a GPU is only capable of running specific, dedicated algorithms, and it cannot combine compute and general-purpose software.
Massively Parallel Single-Chip
The best we have today is the emerging class of distributed manycore processors that contain large numbers of independent cores with closely coupled memory, interconnected through a high-speed Network On Chip (NOC) infrastructure. This approach is becoming mainstream for specialized datacenter systems. One example that is also valid in the embedded space is the Kalray Coolidge™ intelligent processor. This is the third generation of Kalray's MPPA® (Massively Parallel Processor Array) devices. The MPPA architecture ensures determinism and enables the processor, fabricated on a single die, to run different applications and software environments. With 80 independent cores, each equivalent to a modern computing core as found in today's mobiles, Coolidge performs up to 25 TOPS and has typical power consumption of 25 Watts.
Coolidge is conceived as an intelligent processor, adapted to the demands of edge computing in general, and including highly-aggregated automotive computing in particular. It is not only able to handle AI algorithms but can also simultaneously execute diverse workloads such as mathematical algorithms, signal processing, and network or storage software stacks.
In addition to high-performance and power-efficiency, safety and security are key requirements of industrial and automotive edge applications. Freedom From Interference (FFI) between different modules in the system is an important principle in Functional Safety (FuSa) design, as well as spatial and temporal isolation to prevent modules affecting each other and to make sure abnormal programs cannot sap the performance of others.
Go Multikernel to Unleash Multicore
To maximize the performance of the emerging heterogeneous manycore processors while ensuring safety and security through isolation and protection (FFI), a new approach to software is needed -in particular the architecture of the operating system (OS) that brings together the various computing elements.
A multikernel architecture, which can also be described as an arrangement of "distributed microkernels" - as distinct from a microkernel OS - brings these goals within reach. It provides a platform for a system of systems, containing a network of single-core, message-based kernels, as shown on Figure 1. Lightweight message-passing allows fast, deterministic communication at the OS level.
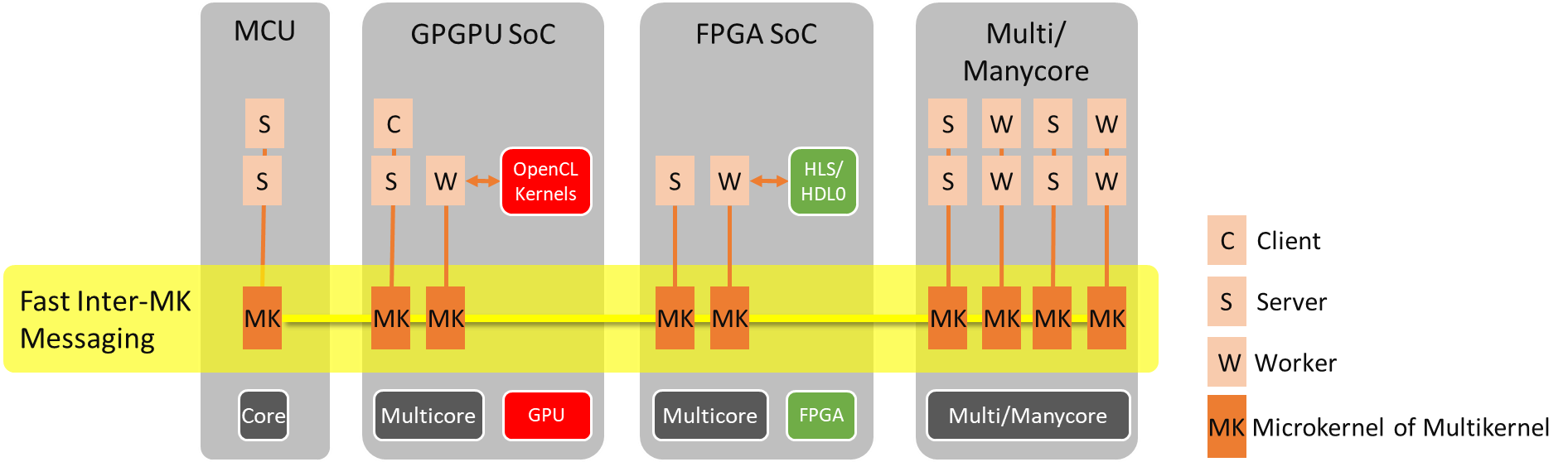
Figure 1. eMCOS "Multikernel" design maximizes Heterogeneous Multicore architectures.
A key property of this architecture is the fact that no kernel instance on any given core can block a kernel instance on another core. This simultaneously ensures much better parallelism, concurrency, and determinism, both at the kernel and the application level.
eSOL's eMCOS® is a distributed-microkernel OS that now enables an independent microkernel to run on each core of the manycore processor while providing a unified platform for high-speed message passing and other functions. Figure 2 illustrates the underlying structure and the ability to handle hard and soft real-time workloads.

Figure 2. eMCOS enables a single, independent microkernel to run on each core.
Moreover, eMCOS POSIX is a multi-process RTOS that provides extended POSIX support and permits multi-cluster organization on one or more separate processors or SoCs. Threads from the same process may run on any combination of cores within a cluster, meanwhile communicating with other threads locally or remotely across clusters.
One advantage of this approach is that this makes the kernel very portable by design. It is therefore capable of serving small core types like Renesas RH850, Infineon Aurix™ TCxx, or an SoC based on Cortex®-R, but can adapt up to much bigger systems like Cortex-A SoCs , or a Kalray MPPA processor.
Bringing together eMCOS POSIX and Kalray's Coolidge third-generation MPPA processor as a multi-accelerator for applications such as vision and lidar processing creates a high-performance platform for advanced autonomous-driving systems, including object tracking and path planning. Advanced industrial use cases also come within reach, such as visual inspection leveraging computer vision and AI algorithms hosted on the same platform.
This approach also provides the flexibility to add performance to an existing system as an accelerator for specific functions such as vision, as shown in figure 3.
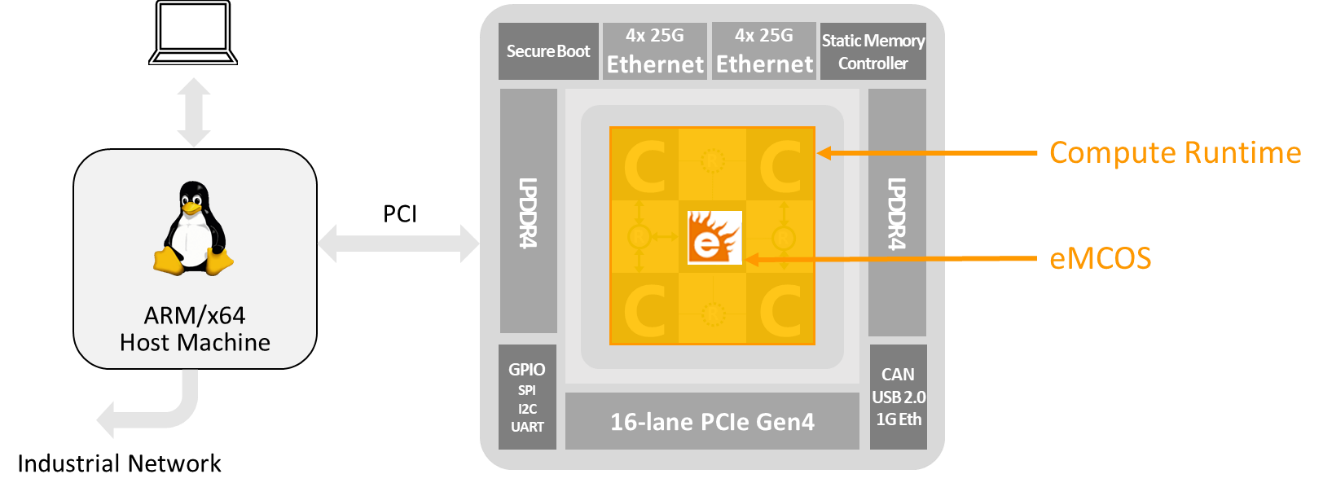
Figure 3. Accelerating the performance of a legacy system with eMCOS and MPPA.
With the focus on aggregation and scalability, eMCOS and eMCOS POSIX enable mixed-criticality systems as in figure 4.

Figure 4. Aggregation of embedded systems with mixed criticality.
The incremental scalability of this distributed-microkernel OS, eMCOS, gives developers the flexibility to innovate with a fully optimized new architecture while also leveraging the best-performing aspects of their existing platforms.
Rolland Dudemaine, VP Engineering, eSOL Europe